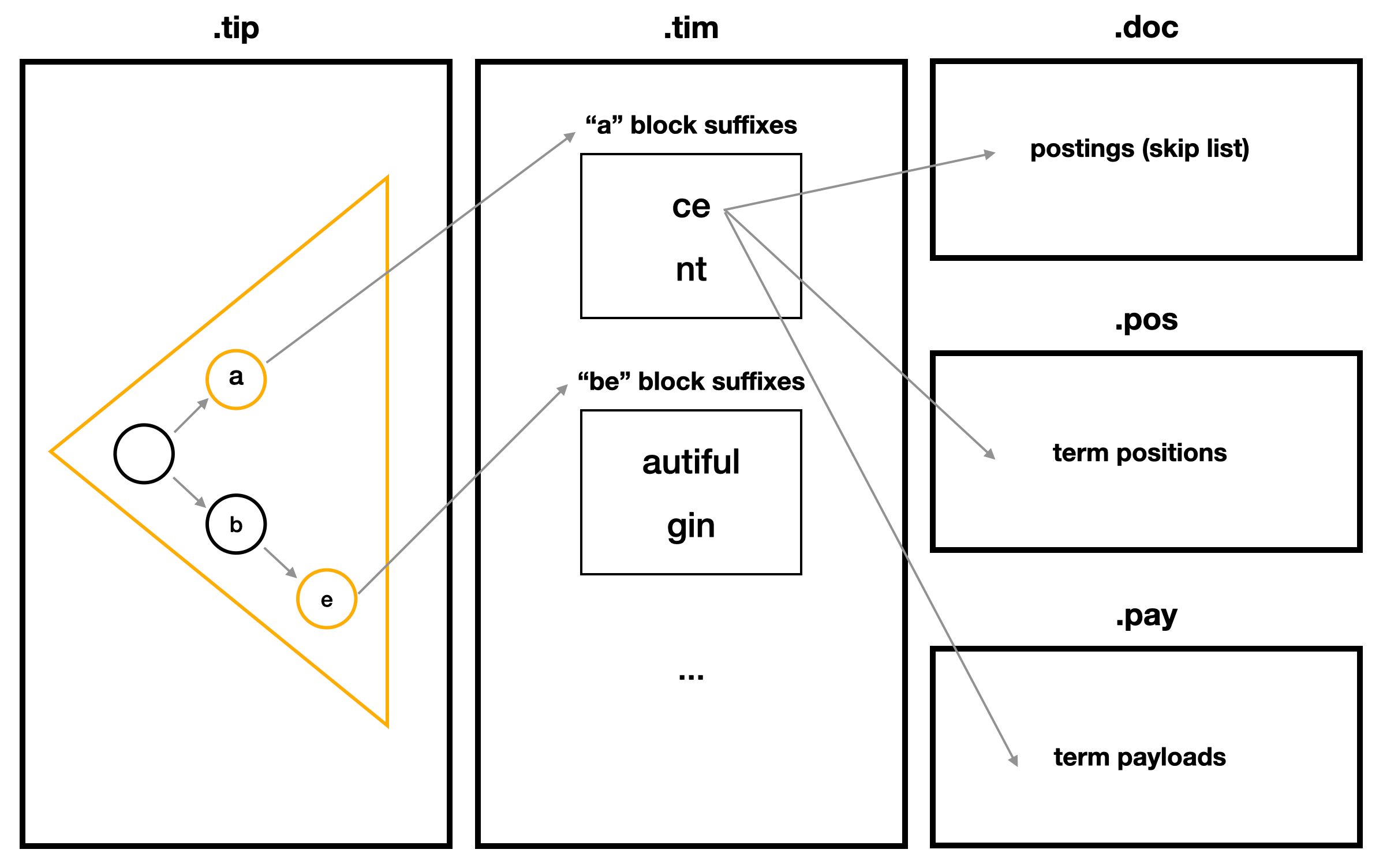
Lucene의 문서 색인의 가장 작은 단위인 Segment 내에 다른 Segment 들과 독립된 색인을 필드별로 생성한다. 그 중 text 타입 역색인은 아래 그림 처럼 크게 3단계로 나뉜다. 예제 데이터는 "ace", "ant", "beautiful", "begin" 단어들로 색인했을 때 루씬 색인 파일 인코딩 구조를 간략화 한 것이다.
doc은 DocId(Segment내 부여된 문서 Id) 들을 저장한 skip list 자료구조. (DocId 들은 오름차순으로 저장하여 delta encoding 적용.)
pos는 term의 위치 정보를 저장.
pay는 term의 payload 정보로 score 계산 시 유저가 추가한 metadata.
심화
Lucene의 역색인은 위처럼 크게 3단계로 구성된다. 이를 깊이있게 살펴보면 왜 term을 저장할 때 prefix, suffix를 나눠서 저장하는 지 의문이 생길 수 있다. Lucene은 전반적으로 검색성능이 떨어지지 않는 선에서 색인의 크기를 최소화하려 한다. 때문에 term에서 공통부분이 많은 prefix는 FST로 저장하고 공통부분이 적은 suffix는 단어를 쪼개지 않고 그대로 저장한다.
FST Burst Tries b -> e | autiful
예를들어 "beautiful" 단어를 저장할 때 "be"로 시작하는 단어는 무수히 많다. 때문에 이 단어를 검색할 때 공통 prefix는 Byte 단위로 하나씩 쪼개 node, arc 형태의 트리를 탐색하는 것이 유리하다. 하지만 "beaut"를 공통 prefix로 가진 단어들은 매우 적다. 때문에 suffix를 FST 구조로 "a -> u -> t -> i -> f -> u -> l" 형태로 만들면 공통부분이 없는데 단어 길이만큼 불필요한 node, arc가 생성된다.
효율적인 역색인을 위해 Lucene은 terms를 사전순으로 정렬하여 순차적으로 25 ~ 48개의 공통 prefix를 찾는다. 공통 prefix를 찾을 때 마다 prefix는 FST에 추가하고 나머지 suffix들은 Burst Tries에 추가한다. suffix 마다 해당 term의 doc / pos / pay FP 도 같이 저장하며 FST는 tip에 Burst Tries는 tim에 serialize 되어 저장한다.
많은 글에서 보조정리를 나열하여 다루지만 이 글에서는 문제 본연의 풀이에 집중하기 위해 해의 존재성과 유일성 각각에 맞춰 풀이한다.
존재성
존재성은 위 연립 합동 방정식을 만족하는 해 $x \in \mathbb{Z}/n$ (쉽게 $0\leq x <n$ 인 정수) 가 존재함을 증명하면 된다. 확장된 유클리드 호제법등 많은 정수론에서 해를 구하기 위해 혹은 존재성을 입증하기 위해 베주 항등식을 인용한다.
베주 항등식
$ a,b \in \mathbb{Z} \ (a \neq 0 \ or \ b \neq 0)$, $gcd(a, b)=d$이면
$ d = au + bv $ 를 만족하는 $ u, v \in \mathbb{Z} $ 가 존재한다.
자세한 증명은 링크를 참조바라며 직관적인 이해는 아래와 같다. 최대공약수 d는 a, b의 특정 배수의 합으로 만들 수 있다는 것이다. 이를 확장한 증명으로 d는 a, b 배수 집합의 가장 작은 양의 정수다. 그리고 d의 배수들로 이 집합을 구성할 수 있다. 즉, a와 b로 나타낼 수 있는 정수 집합은 가장 기본 단위가 d라는 뜻 이다.
나머지 정리의 각 $n_{i}$ 에 대해 $ n_{i}, \frac{n}{n_{i}} $ 를 베주항등식 $ a, b $ 에 대입해보자.
$n_{i}, \frac{n}{n_{i}}$ 는 서로 서로소 이므로 $gcd(n_{i}, \frac{n}{n_{i}}) = 1$
그렇다면 $n_{i}u_{i} + \frac{n}{n_{i}}v_{i} = 1$ 을 만족하는 $u_{i}, v_{i} \in \mathbb{Z} $가 존재한다.
여기서 $e_{i} = \frac{n}{n_{i}}v_{i}$ 라고 하면 아래 두 식이 성립한다.
타원곡선 암호는 줄여서 ECC는 공개키 암호화 방식 중 하나로 데이터 암호화 디지털 인증 등 현재 가장 많이 쓰이는 암호방식이다. ECC는 큰 수의 소인수 분해가 어렵다는 것에 착안해 만든 RSA 암호와 달리 이산로그문제에 착안해 만들어졌다. 때문에 256비트의 ECC키는 3072비트의 RSA키와 비슷한 암호화 레벨이며 키값이 커질수록 RSA보다 암호화 레벨이 급격하게 높아진다.
그래프를 그리면 위와 같이 나타나는데 이 그래프 위의 점들의 집합 G는 아래 조건들을 만족한다.
① G에 속한 임의의 점 P, Q에 대해서 P + Q 또한 G에 속한다 ② (P + Q) + R = P + (Q+ R) ③ ideal point 0이 있으며 P + 0 = 0 + P = P ④ Q가 P의 역원이면 P + Q = 0 ⑤ P + Q = Q + P
위 조건들 중 만약 두 점 p, q의 합을 단순히 x좌표와 y좌표의 합이라면 ① 식을 만족하지 않는다. ① 식이 만족하는 이유는 타원곡선에서 덧셈연산을 특별하게 정의하고 있기 때문인데, 아래 그림을 먼저 본다.
위 그림처럼 타원곡선에서 두 점 P, Q의 덧셈은 두 점을 지나는 직선과 타원곡선이 만나는 또 다른 점 -R에서 수직선을 그어 타원곡선과 만나는 점 R이다. 때문에 타원곡선에서 두 점의 합은 타원곡선에서 속한 점이다. 여기서 P, Q를 지나는 직선과 만나는 또다른 점을 -R이라고 한 이유는 -R이 R의 역원이 되기 때문이다. -R과 R은 수직선으로 이 직선과 타원곡선이 만나는 또 다른 점은 없다. 즉 R + (-R) 연산은 기하학적으로 타원곡선과 만나는 점이 없으므로 0(ideal point)으로 표현한다.
만약 같은 P를 더하면 어떻게 될까? 같은 점을 더하면 위 그림처럼 해당 점의 접선과 타원곡선이 만나는 또다른 점 -R에서 수직선을 그어 만나는 점 R이다. 이와 같이 타원곡선의 덧셈에 대한 정의로 타원곡선의 점은 스칼라 곱셈 연산도 표현 가능하다. 예를 들어 7P는 4P + 3P로 이며 4P는 2P + 2P, 3P는 2P + P 이므로 P의 덧셈연산을 거듭해서 구하다보면 P의 모든 스칼라 곱도 구할 수 있다.
이를 먼저 기울기 m에 대해 정리한 식에 대입하면 아래와 같이 R의 x값을 구할 수 있다.
$x_P + x_Q + x_R = m^2$ $x_R = m^2 - x_P - x_Q$
R의 x값을 직선의 방정식에 대입하여 R의 y값도 계산한다.
$y_R = m(x_R - x_P) + y_P$
② 같은 점 P 2개의 덧셈을 구할 때
점 P에서 타원곡선의 접선의 기울기 m은 타원곡선의 미분방정식에 점 P를 대입한 값이므로 아래와 같다.
$m = \frac{3x_P^2 + a}{2y_P}$
그리고 결과 R은 같은 점을 더했으므로 Q값 대신 P값을 넣어 아래와 같이 정리할 수 있다.
$x_R = m^2 - 2x_P$ $y_R = m(x_R - x_P) + y_P$
유한체에서 타원곡선
위에서 그래프로 나타낸 타원곡선은 무한대 실수 범위이다. 하지만 타원곡선을 이용해서 암호화에 적용하려면 유한한 자연수 범위에서 덧셈연산도 역으로 추적하기 어려워야 한다. 타원곡선암호는 모든 점들을 큰 소수 p에 대한 나머지들, 즉 𝔽p 내에 존재한다. 만약 𝔽p에서 점 P(x, y)가 타원곡선 E에 있다면 x, y는 모두 소수 p의 나머지 들이고 타원곡선 식도 mod p에서 만족하면 된다.
나머지연산에서 나눗셈은 위와 같이 해당 값의 역원을 찾아서 곱셈으로 표현할 수 있다. 이는 앞서 포스팅한 RSA 암호에서 확장된 유클리드 알고리즘이나 페르마의 소정리를 참고하면 구할 수 있다. (아래 참고로 링크한 andrea corbellin blog에서는 확장된 유클리드 알고리즘을 사용하였으나 소수에 대한 나머지 연산이므로 페르마의 소정리를 사용하는 편이 더 쉬운듯 하다. 역원을 구할 때 시간 복잡도는 O(log p)로 비슷하다.)
𝔽p에서 덧셈연산과 스칼라 곱 계산을 통해 얻은 타원곡선 위의 점들은 이산로그문제가 된다. 이를 좀 더 간단히 설명하자면
$ 2^n = 64$ ${2^n \equiv 9\ (mod\ 17)}$
위에 n값는 6으로 쉽게 구할 수 있지만 mod 17에서 2의 배수 중 9가 되는 값은 일일이 계산해 보지 않는 이상 어렵다. 타원곡선 점들도 이와 같이 몇 번의 덧셈연산으로 결과 값을 구하긴 쉽지만 기준 점으로 부터 몇 번의 연산을 했는지는 구하기 매우 어렵다. 타원곡선암호란 구하기 어려운 몇 번의 덧셈을 해야하는지 위에 이산로그문제에서 지수가 되는 부분을 비밀키로 하고 그 결과가 되는 점을 개인키로 한다.
위처럼 유한체에서 타원곡선은 모든 연산을 유한한 범위의 자연수로 표현가능하고 역방향으로 추적을 어렵게 한다. 하지만 이를 바로 암호화에 사용하기에는 몇가지 검증 작업을 더 거쳐야 한다. andrea corbellin blog에서는 아래 식을 예로 들었다.
그리고 기준점에 대해 스칼라 곱을 순차적으로 구해보면 위와 같이 점 5개가 반복해서 나타난다. 위 타원곡선을 암호화에 사용한다면 5번의 연산만으로 사용자의 비밀키를 추적할 수 있다. 물론 암호화에서는 큰 소수를 나머지연산에 사용하겠지만 위에서 봤듯이 mod 93인데 기준점과 타원곡선에 따라 표현할 수 있는 점이 5개 밖에 나오지 않는 경우도 있다.
이처럼 유한체에서 어떤 타원곡선이 표현할 수 있는 총 점의 수는 암호화 레벨을 결정하는 중요한 요소이다. 그리고 현재 이를 구할 수 있는 알고리즘으로 Schoof's algorithm이 있다. (이 알고리즘은 Hasse's theorem on elliptic curves과 중국인의 나머지정리를 기반으로 만들어졌는데, 아직 이해하지 못해 추후 따로 포스팅할 까 합니다. 그리고 타원곡선 표준에서는 이 알고리즘을 통해 미리 정해진 타원곡선과 기준점, 유한체의 범위를 사용하므로 새로운 타원곡선을 만들지 않는 이상 직접적으로 Schoof's algorithm을 사용할 일은 없습니다.)
키 생성
타원곡선 암호에서 키 생성을 위해 domain parameters를 정해야 한다. domain parameters는 a, b, N, n, h, G로 총 6개이다. 먼저 a, b는 타원곡선 식의 요소이고 p는 유한체 범위를 결정하는 소수이다.
그리고 a, b, p값으로 타원곡선의 총 점의 수 N값은 Schoof's algorithm을 통해 구한다. 그 뒤 기준점이 되는 G와 n, h는 아래 순서를 반복해서 구한다.
① 전체 집합 원소의 수 N에서 부분집합의 수인 n을 결정한다. (n은 소수이면서 N의 약수) ② 보조 인자(cofactor)인 h = N/n 를 구한다. ③ 타원곡선 위 임의의 점 P를 골라서 기준점 G = hP를 구한다. ④ G가 0이면 다른 P를 골라서 반복한다.
domain parameters를 모두 정하면 이제 공개키와 비밀키를 만들 수 있다. RSA 암호와 달리 타원곡선 암호에서는 비밀키를 먼저 정한다.
비밀키 d는 [1 ... n-1] 에서 자연수 값으로 키 생성자가 지정할 수 있다. 그리고 공개키는 타원곡선 위의 좌표 H = dG이다.
위에서 domain parameters를 결정하는 과정은 d(비밀키)와 domain parameters로 부터 공개키를 구하는 것은 쉽지만 H(공개키)와 domain parameters로부터 비밀키를 구하는 것은 어렵게 설계되있다. 이렇게 역추적하려면 어려운 이산로그문제를 풀게 하는 것이 타원곡선암호의 핵심이다.