배경
Lucene의 문서 색인의 가장 작은 단위인 Segment 내에 다른 Segment 들과 독립된 색인을 필드별로 생성한다. 그 중 text 타입 역색인은 아래 그림 처럼 크게 3단계로 나뉜다. 예제 데이터는 "ace", "ant", "beautiful", "begin" 단어들로 색인했을 때 루씬 색인 파일 인코딩 구조를 간략화 한 것이다.
색인구조
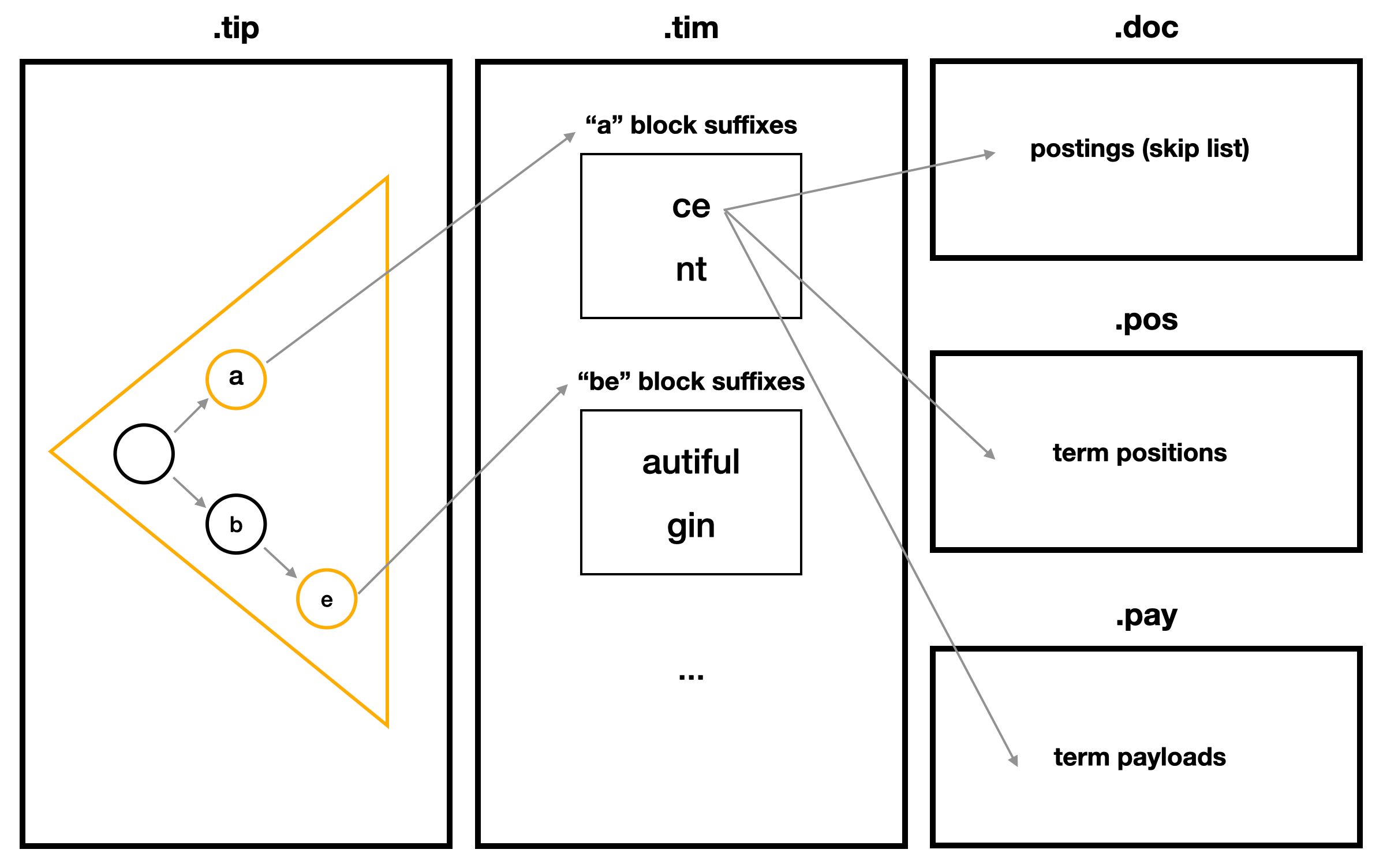
1. tip
- terms(문서에 포함된 단어들)의 공통 prefix들을 저장하는 FST 자료구조.
- input은 term의 prefix, output은 tim의 FP(파일 포인터).
- term을 일정간격(BYTE1, 2, 4 지원)으로 잘라서 노드를 구성하며 트리 형태로 map 구현.
- FST는 input들의 공통 노드에 겹치는 output을 분리하여 저장하여 크기를 최소화 함.
- Direct Construction of Minimal Acyclic Subsequential Transducers 논문 기반.
- Lucene core util FST에 구현됨.
2. tim
- terms의 suffix들을 저장하는 Burst Tries 자료구조.
- 25 ~ 48개의 elements를 묶어 하나의 block을 생성. (위 예시는 실제와 달리 단순화를 위해 2개로 생성함)
- element는 suffix 또는 하위 block을 가리킴.
- suffix는 해당 term의 doc / pos / pay 의 시작 FP를 저장.
- block 내 하위 block은 특정 term이 아닌 모든 terms를 알파벳 순으로 찾기 위함이며 이는 Segment 병합 시 필요.
- Burst Tries: A Fast, Efficient Data Structure for String Keys 논문 기반
- Lucene core codecs lucene90 blocktree에 구현됨.
3. doc / pos / pay
- doc은 DocId(Segment내 부여된 문서 Id) 들을 저장한 skip list 자료구조.
(DocId 들은 오름차순으로 저장하여 delta encoding 적용.) - pos는 term의 위치 정보를 저장.
- pay는 term의 payload 정보로 score 계산 시 유저가 추가한 metadata.
심화
- Lucene의 역색인은 위처럼 크게 3단계로 구성된다. 이를 깊이있게 살펴보면 왜 term을 저장할 때 prefix, suffix를 나눠서 저장하는 지 의문이 생길 수 있다. Lucene은 전반적으로 검색성능이 떨어지지 않는 선에서 색인의 크기를 최소화하려 한다. 때문에 term에서 공통부분이 많은 prefix는 FST로 저장하고 공통부분이 적은 suffix는 단어를 쪼개지 않고 그대로 저장한다.
FST Burst Tries
b -> e | autiful
- 예를들어 "beautiful" 단어를 저장할 때 "be"로 시작하는 단어는 무수히 많다. 때문에 이 단어를 검색할 때 공통 prefix는 Byte 단위로 하나씩 쪼개 node, arc 형태의 트리를 탐색하는 것이 유리하다. 하지만 "beaut"를 공통 prefix로 가진 단어들은 매우 적다. 때문에 suffix를 FST 구조로 "a -> u -> t -> i -> f -> u -> l" 형태로 만들면 공통부분이 없는데 단어 길이만큼 불필요한 node, arc가 생성된다.
- 효율적인 역색인을 위해 Lucene은 terms를 사전순으로 정렬하여 순차적으로 25 ~ 48개의 공통 prefix를 찾는다. 공통 prefix를 찾을 때 마다 prefix는 FST에 추가하고 나머지 suffix들은 Burst Tries에 추가한다. suffix 마다 해당 term의 doc / pos / pay FP 도 같이 저장하며 FST는 tip에 Burst Tries는 tim에 serialize 되어 저장한다.
다음
Lucene 역색인(Inverted Index) 심층분석 2 - FST
선행 이번 글은 Lucene 역색인 전체구조에서 FST 구조만 설명합니다. Lucene의 FST는 Direct Construction of Minimal Acyclic Subsequential Transducers 논문을 기반으로 하며 TestFSTs 로 테스트할 수 있다. 목표 전체 역
chocolate-life.tistory.com
반응형
'검색' 카테고리의 다른 글
| Lucene ANN 분석1 - HNSW algorithm (0) | 2023.02.07 |
|---|---|
| Lucene 역색인(Inverted Index) 심층분석 3 - BlockTreeTerms (0) | 2023.02.06 |
| Lucene 역색인(Inverted Index) 심층분석 2 - FST (0) | 2023.02.03 |